by David Croft, Stephen Brown and Simon Coupland
1. Introduction
Whilst digitisation projects have been under way at Gallery, Library, Archive and Museum (GLAM) institutions for decades,1 the main focus of these projects has traditionally been one of conservation. It was not until relatively recently that increased collection access became a primary motivator.2 Although the spirit of increased access has been enthusiastically embraced by the GLAM community as evidenced by the rapid increase in the number of internet accessible collections, the tools available for searching these collections have not shown the same rapid changes. The majority of collection search systems are still reliant on keyword based search systems. Given the increasing quantity of information being both digitised and subsequently made available online, the limitations of such search systems are becoming more and more evident.
De Montfort University in Leicester, UK hosts the digitised exhibition catalogues for the Royal Photographic Society (RPS) photographic exhibitions held between 1870 and 1917.3 As a contemporary record of the state of photography during this important period in the development of photographic technology the amount of associated information in the Exhibitions of the Royal Photographic Society (ERPS) collection makes the resource unique as well as highly valuable to photo-historians.
The ERPS collection contains information on 34,917 photographs; information such as the title of the photograph, exhibitor’s name, photographic process used, date exhibited and prizes won. Conspicuously absent however are copies of the photographs.4 Out of all the records exhibited, the ERPS collection contains representations of just 1,040. A minority of these are reproduction prints and as such record the exhibited image relatively faithfully, however the majority of the representations are sketches which were made at the time of the exhibitions and the fidelity of these is suspect.
Figure 1: Example section from the original ERPS catalogues.

This article describes research which was conducted at De Montfort University between the School of Media and Communication and the Centre for Computational Intelligence (CCI) to investigate if it would be possible to locate the ‘missing’ ERPS photographs in other (now easily accessible via the internet) GLAM collections. The hope was that by using computational intelligence techniques, the ‘missing’ photographs could be located more effectively than would otherwise be possible via a manual search using the mainly keyword based search interfaces available.
2. Challenges
There are several major stumbling blocks that are encountered when trying to match ERPS catalogue records to those held by other institutions.
- The size of the search space – When searching for a specific photograph the first problem is the sheer number of collections that the image could be stored in. As the collections are not linked, each additional institution requires a separate set of searches to be conducted.
- Digitisation backlog – Whilst millions of historical photographs have been successfully digitised, millions more exist only in analogue form. Whilst this does not completely prevent them being searched, it massively increases the difficultly, resources and time needed to do so.
- Record formats – Along with the multitude of interfaces which need to be navigated, the records themselves are presented in markedly different ways in different collections. Different pieces of information are available in different collections and the names of the fields vary.
Representational State Transfer (REST) and SPARQL Protocol and RDF Query Language (SPARQL) Application Programming Interface (API) interfaces offer a means to access collection records simply without resorting to tricky, fragile and time consuming steps such as developing screen scraping. Making an API available for a collection means that software developers can quickly and easily create new tools that can utilise existing collections. Whilst the number of institutions with collections APIs is small when compared to the number with some form of online collection presence, the number is growing.
To simplify the research we have looked mainly at those collections with API access, however there is no reason that other collections could not be added if more time and resources were available. The collections with APIs that we chose to use are the Brooklyn Museum (BkM), DigitalNZ (DNZ), the Library of Congresss (LoC) and the Victoria and Albert Museum (V&A). These collections offered a large amount of variation with regards to their collection sizes, record formats and record quality and were chosen so as to offer a representative sample of the types of data format and issues of GLAM collections as a whole.
3. Co-reference Identification
The challenge of locating the `missing’ photographs is one of co-reference identification. Also called record linkage, entity resolution, de-duplication or similar, depending on the subject area. The aim is to identify when two sets of metadata are referring to the same item.5 As co-reference problems appear in many subject areas, a large number of methods for identifying co-reference connections have been developed and established.
These include:
- Rule based systems (including expert systems) – A series of IF-THEN statements which attempt what to do for any possible combination of inputs. An expert system has additional capabilities such as being able to explain how and why it arrived at a specific decision but is still based on the same principle. Difficulties in designing effective rules are the main problems for these approaches.
- Neural Networks – A supervised learning approach which learns the rules for identifying co-referent records using a training data set.
- Probabilistic Record Linkage (PRL) – Very popular for linking co-referent records where each record contains multiple independent fields. PRL assigns a probability to each field where the probability value represents the likelihood that a match between that field in two records corresponds to an overall record match. The probability values are typically calculated using a training dataset but they can be derived manually through testing if required.
- Clustering – An unsupervised learning approach. Clustering attempts to group similar items together into separate groups based on inherent structures in the data.
Linking the GLAM records examined in this research appears to be a classic record linkage problem. Each record is formed of multiple fields each containing independent weakly identifying pieces of information. Therefore in order to identify co-referent matches between records as a whole, matches between the individual fields must first be identified. This means we must be able to compare the contents of the individual fields. Unlike traditional record linkage tasks, the contents of GLAM records present a number of interesting and difficult challenges.
4. Query Expansion
The size and number of GLAM collections means that there are far too many records for any of the established co-reference approaches to handle.6 Therefore the first step is to select a subset of the collections which can then be subjected to a more intensive scrutiny.7 In the case of this research we needed to select records with at least a minimal resemblance to the ERPS records that we were trying to locate. The approach we use is a query expanded keywords search. Like a search using a typical search engine, keywords are entered and records which contain those terms are returned. In our research the keywords are automatically identified and then expanded to find synonyms of the original term, for example a query containing the keyword `flower’ would be expanded to include `bloom’, `blossom’, `petal’, `flowers’ etc.
Query expansion is a necessary step since a single photograph can be described in many different ways using a variety of different terms. Depending on factors such as the person describing the image and their institution/domain area terminology, two records describing the same photograph can easily have no terms in common. Searches using just the terms that actually appear in a record could therefore fail to locate valid co-reference matches.
We use WordNet8 as the source of the synonyms for query expansion. The expanded terms also include both the singular and plural forms of both the original keywords and the synonyms selected from WordNet. By returning any record which contains at least one of the query expanded terms, we aim to collect all co-referent records whilst still achieving a massive reduction in the size of the search space.
5. Individual Field Similarity Metrics
Within the ERPS collection, each exhibited photograph has at least some of the following information available for it:
- Title – Often a short factual description of the photograph. However there are examples of emotive or artistic titles (i.e. `Sympathy’).
- Description – A longer description of the contents of the photograph. This field can also contain technical information on the photographic processes used or the location that the photograph was taken.
- Person – The name of the photograph’s exhibitor. This was often also the photographer but this is not guaranteed.
- Process – The photographic processes used to create the image.
- Date – The year of exhibition.
These five fields provide us with the basis for comparison with other collection records.
5.1. Title
Typically a short descriptive piece of text describing the contents of the photograph (e.g. “The chrysanthemum lady”) but this field can also contain artistic or non-descriptive fields (e.g. “Solitude”). The occasional lack of descriptive information is not, however, the biggest problem. The standard approach to comparing pieces of text in order to identify textual similarity is to compare the term vectors for the texts being compared; a term vector being a list of all the words in a piece of text along with the number of times that each of those words appears.
Whilst this approach is simple and highly effective, it works best when large pieces of text are being compared (hundreds or potentially thousands of words). The title fields of the GLAM records contain significantly fewer terms, nine on average.9
Given the briefness of the text and number of ways in which a single image can be described, it is therefore highly unlikely that the same terms will appear in title fields being compared even when the same image is being described. This is the same issue that promoted the use of query expansion.10 Statistical approaches such as this are therefore ineffective.
Semantic similarity techniques offer an advance on purely statistical approaches. These take into account similarities in the meanings of the terms being compared. This means that two fields being compared do not need to contain the same terms in order to be considered similar, the only requirement is that the terms from each field have similar meanings. The term similarity values are used to create semantic term vectors which can then be compared using standard term vector comparison methods.
Whilst established semantic approaches11 are effective, they are very computationally expensive. Too expensive for use in comparing large numbers of GLAM records. Therefore in our research we have developed a simplified semantic similarity measure called Lightweight Semantic Similarity (LSS) which significantly lowers the computational complexity at the cost of statistically insignificant reductions in the accuracy of the results.
Table 1: Example title fields and similarities.
| Field | Calculated Similarity | |
| A | B | |
| “the chrysanthemum lady” | “the chrysanthemum lady” | 0.91 |
| “a woman selling flowers” | 0.76 | |
| “to the ladies” | 0.77 | |
| “the cat in the hat” | 0.50 |
5.2. Description
A longer (than title) piece of descriptive text. This field can contain information about the photographer, the contents of the image, the photographic processes used, location where the image was taken and more. However a large number of records leave this field empty. Due to the degree of variation in this field between records and collections, we were unable to devise an appropriate similarity metric and so this field is ignored.
5.3. Person
In the case of the ERPS collection this field contains the name of the exhibitor of the photograph at the relevant exhibition. This is often also the person that took the photograph but this is not guaranteed. In other collections this field can contain the name of the original photographer, the owner of the photograph or the originating organisation (i.e. “Bain News Service”). Name comparison is a well established problem in many areas and as such a large number of algorithms exist in order to compare names which can handle typographical errors, alternative spellings etc. The records of GLAM collections include an additional challenge – the order of the names in the fields is unknown. Whether a name in a field is listed as firstname lastname or lastname firstname varies not just between collections but often within an individual collection.
The approach that we created for comparing the person fields uses a combination of Jaro-Winkler12 to handle typographical errors, variations in spelling and initials of full names with a best _t approach designed to compare the individual name elements regardless of their order in the original fields.
Table 2: Example person fields and similarities.
| Field | Calculated similarity | |
| A | B | |
| “h.t.malby” | “malby, henry thomas” | 0.92 |
| “miss frances b johnston” | “johnston, frances benjamin 1864-1952” | 0.79 |
| “david croft” | “john smith” | 0.47 |
5.4 Process
The photographic processes that were used in the creation of the image. This field has the typical problems of typographical errors and multiple formats but there are several additional complications. The first of these is that most of the fields only list some of the processes that were used. Many of the historical photographs that are contained in GLAM collections required several separate processes in order to produce the final image that would today be called a photograph. Often one process was required to produce the initial negative image and a different process to produce the positive print from that negative. However the process field will typically list one or the other of these, not both.
The second major issue is that of process misidentification. A proliferation of different processes occurred during the time period examined for this research, the results of different processes are not always easily distinguished and can require access to the original physical photograph in order to distinguish it at all.13 Historic photographic collections are known to contain a high level of process misidentification14 although we are not aware of any research that has been conducted into the extent of this problem. However it can be safely assumed that processes are most likely to be misidentified when they closely resemble each other. Albumen prints and Collotypes are more likely to be misidentified as each other than Collotypes and Daguerreotypes for example given that both Albumen and Collotypes are both made of paper and Daguerreotypes are on metal. Therefore a metric for comparing fields must be able to identify more than just variations in the name of a single process, but also the relative similarities of separate processes in order to account for potential misidentifications.
The technique created for this research matches the contents of the initial process fields to a list of pre-set keywords describing various known processes. This allows the approach to handle typographical errors and spelling variations. The various photographic processes are organised into a dendogram with processes sharing specific traits appearing on the same branch. Once the field has been matched to a specific focus, it can be compared to other fields using a graph traversal algorithm that simply finds the shortest path between the processes. The shorter the distance between the approaches, the more similar they are considered to be.
Table 3: Example process fields and similarities.
| Field | Interpreted as | Calculated similarity | ||
| A | B | A | B | |
| “tintype” | “tin type” | tintype | tintype | 1.00 |
| “teentaype” | tintype | 1.00 | ||
| “ferrotype” | tintype | 1.00 | ||
| “daggerotype” | daguerrotype | 0.75 | ||
| “oxymel” | collodion | 0.25 |
5.5. Date
There are three main factors to consider here. Firstly there is the sheer range of different formats that the dates appear in. Dates stored in a computer readable format (e.g. dd/mm/yy or yyyy/mm/dd) represent a relatively simple challenge and although it is not always possible to distinguish between the numbers that represent the day and those for the month, the year can normally be easily extracted. Difficulties arise when the date fields contain human readable text instead (e.g. “the nineteenth century”). Secondly, there is the amount of time between the dates described in the fields. The greater the amount of time between the fields the less similar they are. Thirdly, the time spans that the individual fields describe. Many date fields described a span of time rather than a specific date or year (i.e. “1890s”, “the nineteenth century”). The greater the time spans the less similar the fields. For example “19th century”15 versus “1900” is less similar than “1900s” versus “1900”.
Our approach combines three separate sub-similarities based on the average time span of the two date ranges being compared, the time difference between the start of the two spans and the difference between the ends of the two spans.
Table 4: Example date fields and similarities.
| Field | Interpreted as | Calculted similarity | ||
| A | B | A | B | |
| “1900” | “1901” | 1900 | 1901 | 0.98 |
| “1900” | “1900s” | 1900 | 1900-1909 | 0.91 |
| “1900s” | “1900s” | 1900-1909 | 1900-1909 | 0.93 |
| “1900” | “19th century” | 1900 | 1800-1899 | 0.33 |
| “1900” | “1999” | 1900 | 1999 | 0.33 |
6. Overall Record Similarity
Having described our methods for comparing the individual fields, attention is now turned towards methods for combining the individual field values into overall record similarity values.
6.1. Clustering
Initially a clustering approach was attempted in order to combine the individual fields into an overall record similarity and to group the co-referent records together.
The field similarity values were treated as a distance between two records, each similarity representing a separate dimension. Overall record similarity could then be calculated as the distance between the records.
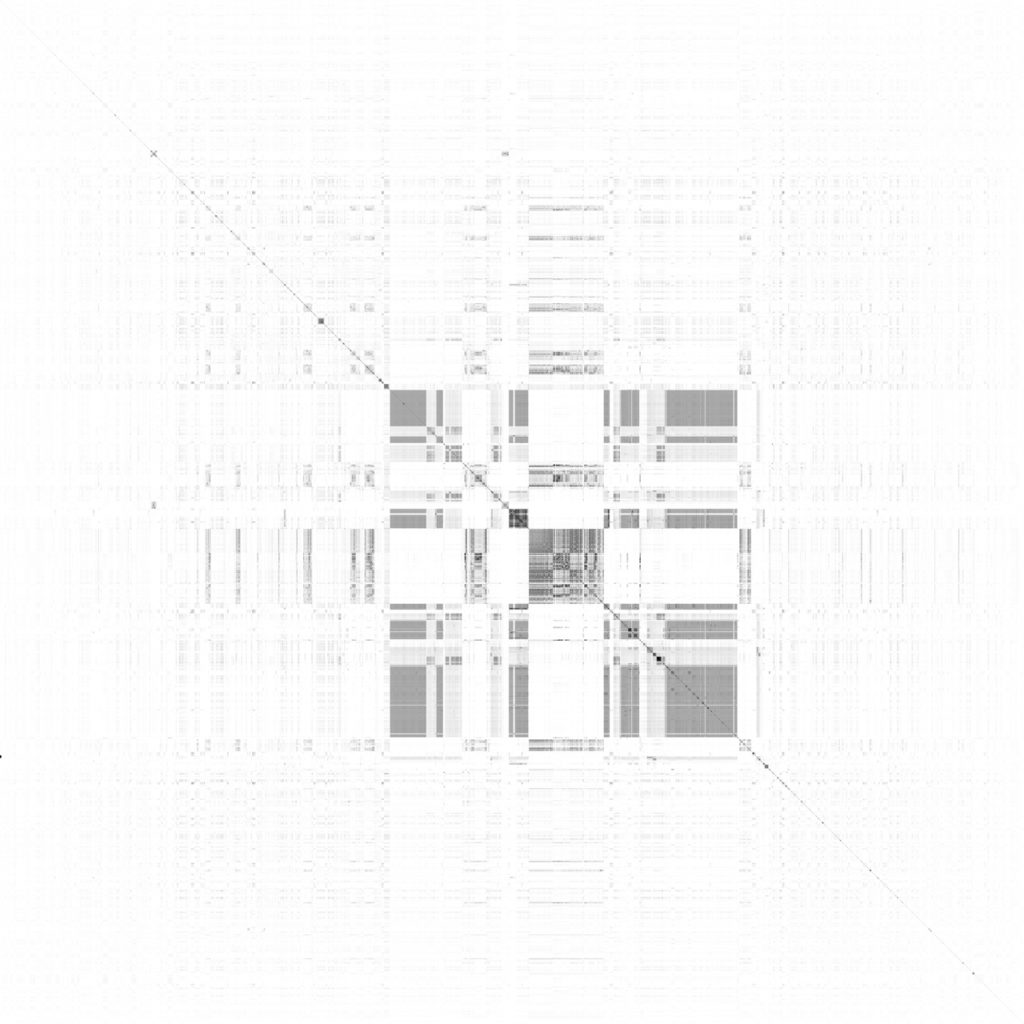
Cluster tendency was tested using Visual Assessment of cluster Tendency (VAT) images of both the pair-wise similarity matrices of the individual fields and the overall records. VAT images are a simple method of visually assessing likely cluster tendency and the probable sizes and number of clusters. Clusters appear as squares along one diagonal in VAT images with the size of the squares correlating to the size of the clusters and the number of squares correlating to the number of clusters. The VAT images (Figure 3) showed some evidence of cluster tendency. However when clustering was actually attempted, the clusters produced did not group together records based on the content on the records but instead had a tendency to group records together according to the originating collections of the records. When comparing records which originated from the same collection, the average similarity value was higher than when comparing records from different collections due to reasons of format and terminology. Clustering was therefore deducing the originating collection using the title, person etc fields. Although this was not of use with regards to the goals of this research it is an interesting result. That clustering could be affected in this manner clearly demonstrates that the cataloguing at the various institutions have a noticeable effect on the records which affects the searching of those records.
Figure 2: Example data points and corresponding VAT image. [a) Data points b) VAT image]

Figure 3: VAT image for erps17654.
6.2. Rule Based/Dendogram
Rule based approaches were avoided initially as the similarity metrics for the individual fields were unable to produce yes/no answers as to whether or not any a fair of fields matched or not. However, with the apparent failure of clustering as a viable technique, rule based approaches were reconsidered – specifically a Fuzzy Inference System (FIS).
Fuzzy logic is a form of multi valued logic which uses fuzzy sets. This is in contrast to traditional or crisp logic where membership of a set must be either true or false. This ability to model partial set membership gives fuzzy logic a greater resilience to vague, imprecise and noisy inputs when compared to crisp logic. Given the difficulties that were encountered when comparing the individual record fields, fuzzy logic appeared eminently suited.
For this research we created a series of fuzzy rules which combine the individual field similarity values into overall record similarity values. The use of fuzzy logic allows the resulting record similarities to be calculated despite the imprecise field similarities.
Having identified the similarities between the records the similarity values were used to order and sort the records using a custom dendogram16 generation algorithm in order to identify the most promising co-reference links.17 The record that is being searched for (the seed record) becomes the root node of the dendogram and its immediate child nodes represent the most promising matches to that record as determined by our approach. The advantage of this technique as opposed to just selecting the top-n records with the highest similarity to the seed record is that our approach groups similar records together within the dendogram. Once one image by a specific photographer is found for example, the rest of that individual’s work is likely to be linked to it. This means that even if the ‘perfect’ co-referent match is not immediately linked to the seed record due to variations in how the image is being described etc, as long as some image by the same photographer/of the same subject is found, the perfect match record can be linked to that and so appear in very close proximity to the seed record. For example, erps2840918 has a title of “george meredith”, our dendogram identifies loc9251246619 as the best possible match. However it also identifies vaO101352 as a very promising match and a series of records all by “hollyer, frederick” as being good matches to vaO101352 including vaO75248.20 Whilst vaO101352 ranks quite highly in terms of co-reference to erps28409, vaO75248 is a near perfect match, erps28409 being just an enlargement of vaO75248.
Figure 4: Top 100 records in the erps28409 dendogram.

Figure 5: Enlargement of the top records from Figure 4.
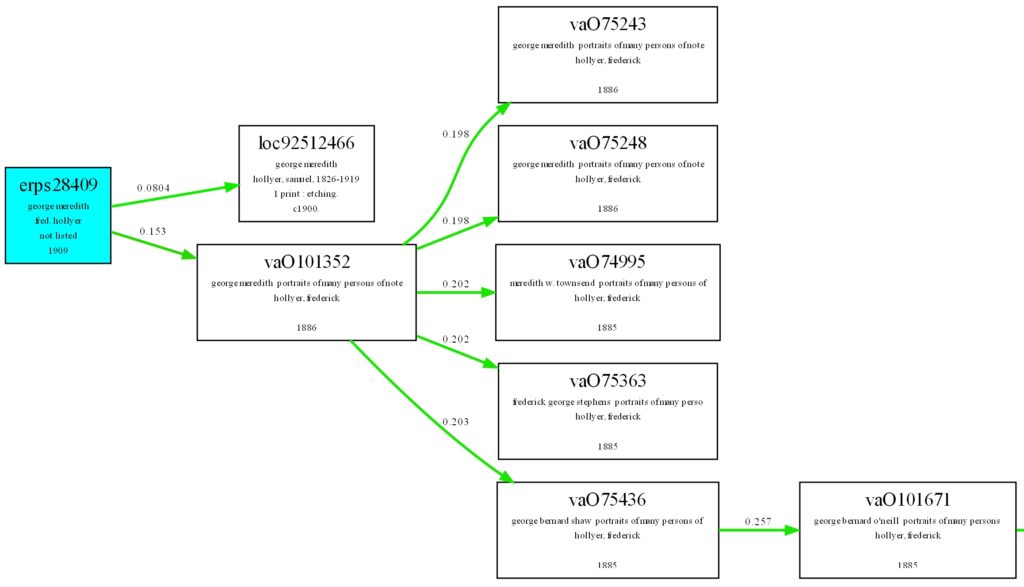
Table 5: Co-reference candidates for erps28409.
| Id | erps28409 | loc92512466 | va075248 |
| Title | George Meredith | George Meredith | George Meredith: portraits of manu persons of note by Frederick Hollyer |
| Person | Fred Hollyer | Hollyer, Samuel, 1826-1919 | Hollyer, Frederick |
| Process | Not listed | 1 print: etching | Not listed |
| Date | 1909 | c1900 | 1886 |
| Image |  |  |  |
7. Validation
In order to test the validity of the techniques described here, volunteer curators and historians were engaged to compare manual searching for similar records with computationally generated results.
The volunteers were asked to select three records from a list of 795 records taken from the ERPS collection.21 They were allowed to select any records they wished in the hope that if they could choose records in which they were interested they would invest serious effort in the search task. When manually searching, the participants were allowed to search in any manner, using any tools that they wanted, however they were asked to restrict themselves to finding records from the six collections looked at as part of this research.22 One of the first things to be done as part of future work with this research is to expand the number of collections that the new approach can examine but at the present time and as a proof of concept only six are included. The participants were also all asked to search for the same two additional records.23 The reasons for this were twofold, firstly the vast majority of records in the ERPS collection were not expected to have co-reference candidates in other collections. This meant that regardless of the effectiveness of either search approach, the majority of searches would produce mediocre results simply because there were no matches to be found. There was a real concern that, without including some records with known co-reference matches, participants could conduct all of their searches without finding a single co-reference candidate.
Having completed their manual searches, the participants were provided with the results found by the new approach. Revealing the existence of co-referent records earlier could have influenced participants’ search behaviours.
Participants were asked to score the relevance of the results they found using the new approach and manual searching. Ranking was recorded on an 11 point closed responses scale ranging from “No relevance” to “Perfect match”. For the purposes of testing a minimally matching record was considered to have been found if the ranking given was greater than five (it appeared in the top half of the scale). The success rates for the two approaches in locating any kind of co-referent match are shown in Figures 6 and 7. Figure 6 shows the rates based on a per search attempt whilst Figure 7 shows the results on a per record basis, i.e. if multiple participants searched for the same record then if even one found a match using manual searching that constitutes a successful result for manual searching. As Figure 7 shows, the match finding rate of the new approach is significantly greater than that achieved by manual searching.
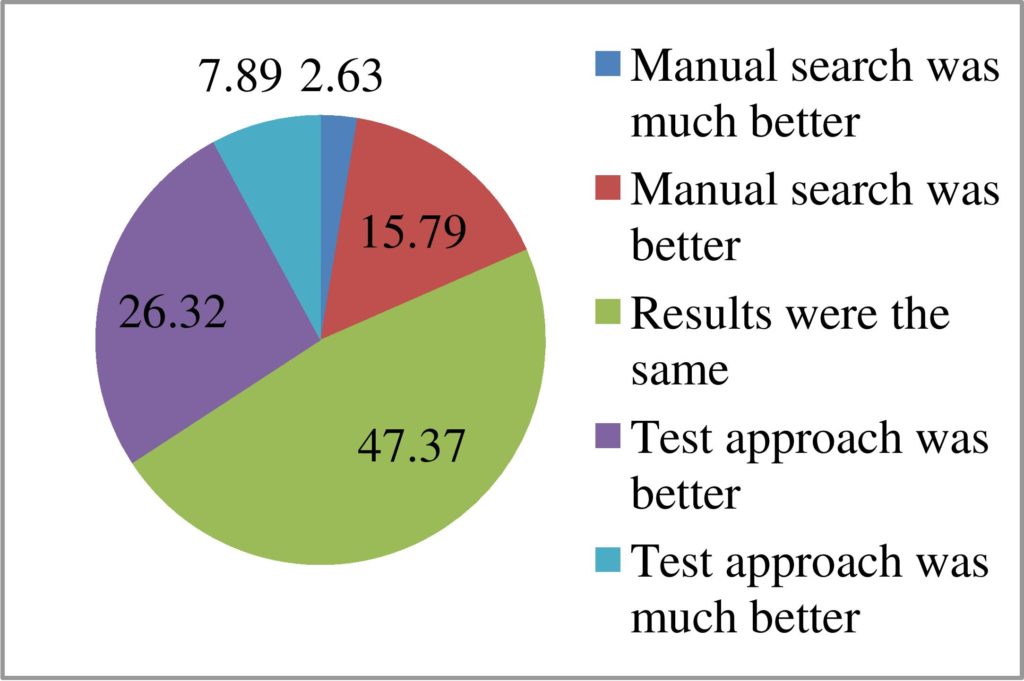
The number of matches found is not the only measure of the success of the approaches however. Whilst the new approach may find more matches, the matches that manual searching does find could still be of a higher quality (closer match) that those of the new approach. However Figure 8 shows which set of results were preferred by the participants across all of the searches conducted and show an apparent preference for our new approach. However this included occasions when no good matches were found (rankings of <= 5). When only records for which both manual and the new approach found good matches, neither approach is preferred over the other.24 This means that match quality for both approaches was seen as equivalent by the test participants.
Figure 6: Recall rates of the search approaches for each search.
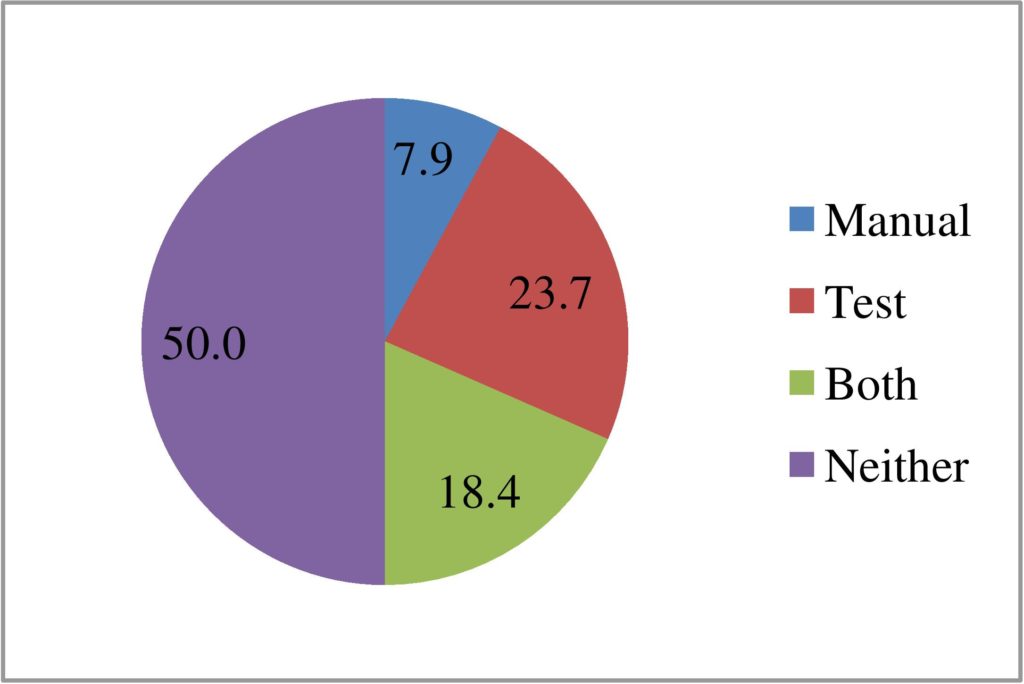
Figure 7: Recall rates of the search approaches for each record.
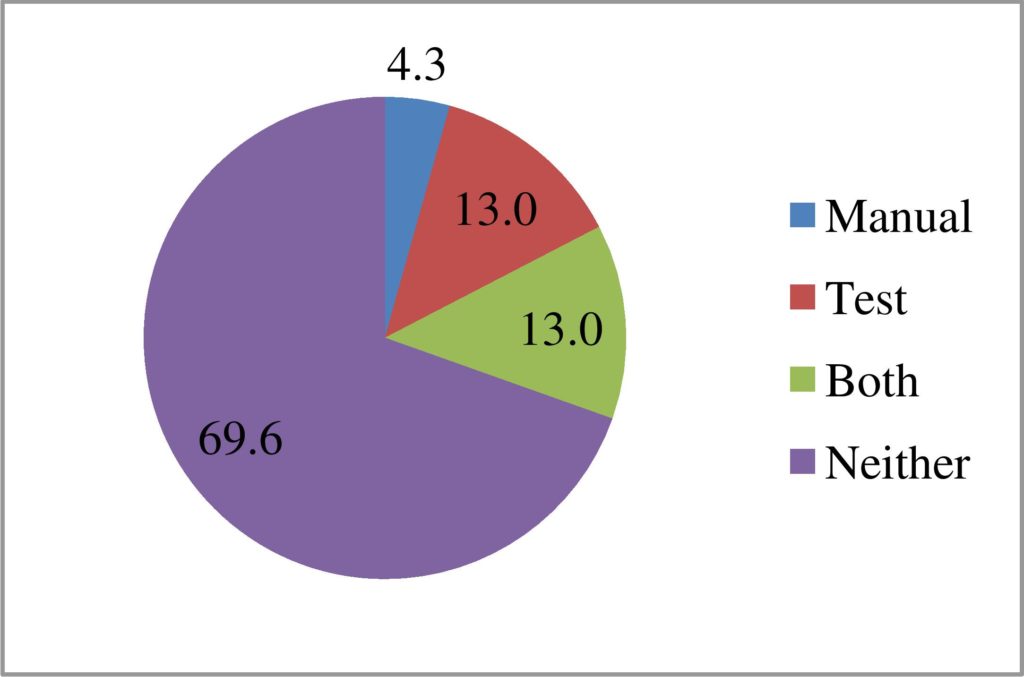
Figure 8: Participant preferred results for each search.
8. Conclusions
Our research demonstrates a valid method for semi-automatically identifying co-referent photographic records across multiple GLAM collections. The approach finds more potential matches than a manual search of the same collections and locates matches of at least equivalent quality to those of manual searching. The new approach is also able to automatically collect and examine records across multiple institutions in less time from a user’s point of view.
The final determination as to whether a potential match is or is not an actual match still needs to be made by a human expert.
- A. Stow. Digitastion of museum collections: a worthwhile effort? Institutionen för kulturvåard, Göteborgs universitet, June 2011. http://hdl.handle.net/2077/26817
- “Status of technology and digitization in the nation’s museums and libraries,” 2006. Available: http://web.archive.org/web/20060926090433/http://www.imls.gov/resources/TechDig05/Technology%2BDigitization.pdf
- “Exhibitions of the royal photographic society 1870-1915”. De Montfort University. October 2012. Available: http://erps.dmu.ac.uk/
- Figure 1.
- That item could be a person, place, date, subject or in the case of this research, a photograph.
- The records collected for this research just for the purpose of testing totalled more than 1.7 million.
- This step is sometimes referred to as blocking or chunking.
- “About wordnet”, October 2012. Princeton University. http://wordnet.princeton.edu/
- Based on an analysis of 1,773,740 records spanning six collections.
- See Section 4.
- Latent Semantic Analysis (LSA), STASIS etc.
- M. Jaro, “Advances in record-linkage methodology as applied to matching the 1985 census of tampa, orida,” Journal of the American Statistical Association, vol. 84, no. 406, 1989. 414-420.
- Attributes such as the texture of the photographs surface can be important and this information is not captured in digital copies of an image. Photographic material. Preservation Advisory Centre – British Library, June 2013. Available: http://www.bl.uk/blpac/pdf/photographic.pdf. J. M. Reilly, Care and Identification of 19Th-Century Photographic Prints (Kodak publication). Eastman Kodak Company, 1986.
- D.C. Stulik and A. Kaplan. Working with the alternative photographic processes community. The Getty Conservation Institute, June 2013. Available: http://www.getty.edu/conservation/publications resources/newsletters/27 1/collaborative.html.
- The 19th century actually ran from 1801 to 1900. However the dates used (1800 to 1899) represent a widespread misunderstanding. These dates used were easier to implement in software. The date similarity values produced are only 0.007 off the `true’ values.
- Tree diagram.
- Figures 4 and 5.
- Copyright 2008 De Montfort University. Database right De Montfort University (Maker). All rights reserved.
- Courtesy of the Library of Congress, LC-USZ62-105804
- Victoria and Albert Museum, London
- The 795 are a subset of the 1,040 ERPS records with image data.
- The Brooklyn Museum (BkM), DigitalNZ (DNZ), Exhibitions of the Royal Photographic Society (ERPS), the Library of Congresss (LoC), Photographic Exhibitions in Britain (PEIB) and the Victoria and Albert Museum (V&A).
- erps17093 and erps28409.
- Manual searching and the new approach each outperforms the other in 18% of search and have an equal performance for 64% of cases.